



Lavorare con i dati ne implica la raccolta di grande quantità, ma anche di differenti tipologie e provenienti da diverse fonti, oltre che velocizzarne il processo stesso di raccolta e quello di analisi. Per realizzare tutto ciò vengono richiesti nuovi approcci architetturali ai dati rispetto al passato. Scopriamo dunque all’interno di questo articolo, realizzato dall’Osservatorio Big Data & Business Analytics del Politecnico di Milano, come abilitare una corretta data architecture nella propria azienda.

Il ciclo di vita dei dati: dalla raccolta alla conservazione
Strutturare un'architettura per la gestione dei dati non è semplice. A dimostrazione di ciò, ecco di seguito i principali motivi:
-
elevato volume di dati generato oggigiorno;
-
alta eterogeneità delle fonti informative;
-
necessità di raccogliere e analizzare i dati in modalità real time;
-
complessità dei modelli analitici;
-
espansione delle operazioni e crescente numero di utenti che accedono a dati e analytics;
-
integrazione con sistemi già esistenti all'interno dell'organizzazione.
L’intera gestione del ciclo di vita del dato richiede l’impiego di nuove tecnologie innovative che abilitino l’estrazione del valore. Vediamo, dunque, che cosa succede durante le singole fasi del ciclo di vita dei dati:
Raccolta dei dati
Nella fase di raccolta dei dati è necessario disporre di un’infrastruttura scalabile in grado di processare anche grandi moli di dati in real time, minimizzando le possibili perdite informative. La fase di analisi richiede la valutazione di architetture dei dati complesse che coniughino capacità di elaborazione più tradizionali con sistemi real time.
Conservazione dei dati
La conservazione dei dati richiede l’impiego di tecnologie in grado di superare i tradizionali database relazionali per gestire le più varie fonti informative.
Integrazione dei dati
In ultimo, ma non per importanza, la parola chiave di un’architettura innovativa è sicuramente integrazione. Diventa basilare, infatti, essere in grado di integrare i dati provenienti dai sistemi di business tradizionali (sistemi gestionali, CRM, ecc..) con quelli derivanti dal mondo dei sensori interconnessi (Internet of Things) e dalle interazioni tra persone sul web o sui social networks (Internet of People).
Come abilitare la data architecture?
Innovare è quindi fondamentale, ma il passaggio dalla teoria alla pratica è tutt'altro che scontato. L’infrastruttura tecnologica di un’azienda si compone infatti di diversi strumenti e componenti da considerare.
Per questo l’Osservatorio Big Data & Business Analytics ha cercato di fare ordine, riassumendo in un unico modello le principali scelte tecnologiche da considerare in una data architecture. Dalla gestione dei dati all’accessibilità, ecco una carrellata utile a comprendere quali sono le tecnologie innovative più diffuse nelle grandi aziende italiane.
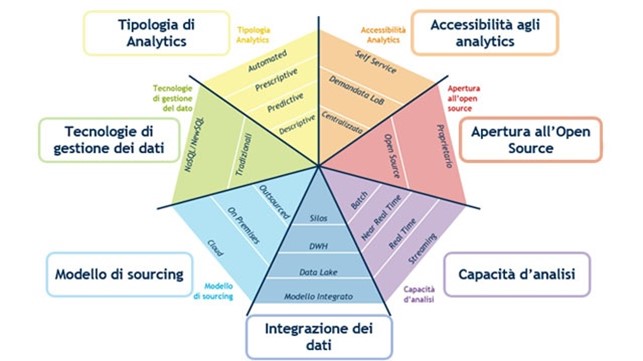
Le nuove frontiere architetturali dei dati
Non si può parlare di tecnologie di architettura dei dati senza nominare Hadoop, framework software per l’elaborazione di elevate moli di dati in modalità parallela. Hadoop, considerato uno dei fattori abilitanti la diffusione degli Analytics, è stato sviluppato in un contesto totalmente Open Source, dall’Apache Software Foundation. Nel tempo sono diverse le tecnologie sviluppatesi all’interno di questa community e numerose le organizzazioni che guardano al mondo open source come un acceleratore d’innovazione, perché permette loro di superare problemi quali i lock-in dei software proprietari. Il 30% delle grandi aziende utilizza oggi questi strumenti.
Un altro trend dalle incredibili potenzialità è il Cloud. L'adozione di architetture Cloud native sta diventando sempre più comune, perché offrono alle aziende la possibilità di accedere a servizi con costi contenuti, garantendo grande scalabilità, automazione e sicurezza. Inoltre, è possibile anche risparmiare nella fase di storage dei dati. Benefici connessi vengono generati anche da architetture Hybrid Cloud, che combinano risorse Cloud pubbliche e private, o Multi Cloud, che coinvolgono l'uso di più fornitori.
Infine, sempre più spesso si parla di architetture a microservizi. In questo ambito il Data Mesh ne riprende la logica. Questo approccio architetturale per la gestione dei dati prevede la scomposizione di applicazioni monolitiche in servizi più piccoli e autonomi, noti come microservizi, che facilita la gestione e la scalabilità delle applicazioni, migliorando la flessibilità e la manutenibilità complessiva dell’architettura.
L’integrazione e la gestione dei dati: oltre il Data Warehouse
L’approccio tradizionale di raccolta dei dati è quello mediante architettura a silos: con questo modello i dati vengono raccolti separatamente da ogni funzione aziendale. Quest’approccio è totalmente inadatto all’estrazione di valore dai dati in contesti organizzativi estesi
Come già detto, però, l’integrazione è una variabile chiave per poter esplorare i dati e scoprire pattern e correlazioni inaspettate. I silos, dunque, non bastano più. Ma non solo: anche il ben noto Data Warehouse – l’archivio informatico di dati strutturati raccolti dai sistemi operazionali aziendali e da fonti esterne – si è rivelato insufficiente. Pertanto, oggi un numero crescente delle grandi aziende affianca o integra il Data Warehouse in un Data Lake, un ambiente di archiviazione dei dati nel loro formato nativo. Il Data Lake utilizza l’approccio “schema-on-read”, in cui la struttura viene creata nel momento in cui i dati vengono utilizzati per le analisi. Questo cambio di prospettiva permette di immagazzinare anche dati non strutturati, quali testi, immagini o video.
Agli strumenti di storage si affiancano tipologie innovative di gestione dei dati. Non solo database relazionali, ma anche basi di dati che superano o rinnovano il linguaggio SQL (si parla per questo di database NoSQL o NewSQL), al fine di migliorarne le performance. Oggi una grande azienda su tre utilizza questi strumenti, tra i più noti i database colonnari e key-value.
L’analisi dei dati e le modalità di accesso agli insight
Entrando nel vivo dell’analisi dei dati, se le analisi descrittive rimangono una necessità e vengono rese ancor più valide e fruibili dagli strumenti di visualizzazione dei dati, le analitiche più avanzate si stanno diffondendo anno dopo anno.
A oggi, circa tre grandi aziende su quattro utilizzano tecniche di Predictive Analytics in alcuni dei loro processi aziendali. Da un punto di vista del business, se attraverso i dati si riesce a prevedere ciò che accadrà nel futuro, sempre di più i decision maker potranno porli al centro delle loro scelte strategiche. La trasformazione di un’organizzazione in una data-driven organization passa poi anche attraverso l’aumento delle persone che possono accedere ed esplorare i dati (in particolare i top manager). Sempre di più ci si riferisce a questo trend con il termine self-service analytics, oggi abilitato da circa il 30% delle grandi organizzazioni.
Infine, investire nel rinnovamento dell’infrastruttura tecnologica può voler dire accelerare le modalità di raccolta e analisi dei dati, superando i sistemi batch. Per i non addetti ai lavori, in questo contesto con il termine “batch” – letteralmente lotto, partita – si intendono i sistemi che si aggiornano periodicamente, nella maggior parte dei casi ogni giorno. Se queste tempistiche potevano essere valide nella raccolta di dati transazionali, si rivelano sempre meno adatte nella raccolta di dati provenienti dai sensori o in tutte quelle situazioni in cui l’analisi tempestiva dei dati può influire sulle principali decisioni di business, auspicabilmente sempre più data-driven.
Vuoi conoscere le potenzialità dei Big Data Analytics e sfruttarli per la tua azienda?
- Autore
Gli ultimi articoli di Alessandro Piva
